30-дневный минималистичный конкурс по рисованию кошек
В течение 30 дней подряд в период с ноября по декабрь 2017 года я рисовал минимальное изображение кошки, используя блокнот размером 9 x 12 дюймов и черный маркер.
(Это было не всегда легко, так как я смотрел на маленький экран мобильного телефона, и обычно кошки и собаки пытались залезть на меня.)
Затем я разместил оригинальное фото + совместный рисунок в Instagram с хэштегами #30dayfminimalistcatdrawingchallenge, #minimalistcatdrawingchallenge, #30daysofminimalistcatdrawings и #minimalistcatdrawing.
Никаких переделок — я просто поделился первым и единственным рисунком, который делал каждый день.
Иногда я воровал фотографии кошек из социальных сетей и рисовал их вместо них.
(Я серьезно задумался о том, чтобы сделать еще одну серию только о людях с велосипедами и кошками, так как многие мои друзья любят кататься на велосипедах, а также заводят кошек.)
Все началось, когда друг поделился ссылкой на Reddit Minimal Cat Art group [» Сообщество, посвященное художественному самовыражению в его самой чистой форме» ] на Facebook, и я прокомментировал — довольно напыщенно, оглядываясь назад — «Я бы преуспел в этом!» а другой друг прокомментировал: «Слова стоят дешево!» — Итак, игра продолжается.
У меня семь кошек, так что у меня достаточно возможностей для свежего визуального контента, лежащего вокруг моего дома на различных мягких, теплых поверхностях. В первые несколько дней я сделал несколько случайных снимков и нарисовал их маркером в своем блокноте, так как это было под рукой. Ничего ценного.
Я получил такой хороший отклик в Facebook и Instagram, и мне было так весело их рисовать, что мне пришла в голову идея 30-дневного челленджа, так как я видел, как другие люди выполняли подобные челленджи по рисованию — #InkTober и #the100dayproject например – и хотел в определенной степени привлечь к ответственности себя.
Примерно через треть месяца мы устроили вечеринку, и дети моей подруги нашли альбом для рисования и раскрасили в нем котиков (я понимаю, почему — они действительно выглядят как страницы раскраски).
Мне нравится, что они это сделали! Ее дочь даже нарисовала собственного кота!
Через несколько дней приехал еще один друг из другого города. Пока нас не было, она взяла альбом и нарисовала одного из наших котов. Это сделало меня счастливым. Больше людей вдохновляются рисовать, творить и самовыражаться!
Пока нас не было, она взяла альбом и нарисовала одного из наших котов. Это сделало меня счастливым. Больше людей вдохновляются рисовать, творить и самовыражаться!
Вот все 30 кошек, которые я нарисовал ⇓
На самом деле я просчитался и сделал 32 рисунка, поэтому в этой сетке не хватает двух.
Что вам больше всего нравится?
Мне больше всего нравится 3-й ряд 1-го столбца: Виго лежит на спине и облизывает переднюю лапу, что он и делает, когда очень счастлив.
Я очень рад, что сделал это. Кажется, это доставляет людям удовольствие, что делает меня счастливым. К тому же я уже много (много) лет говорю себе, что действительно должен рисовать больше. Но у меня никогда не было причин или вдохновения. Это дало мне цель. А с графической записью работы начинаю заниматься все больше и больше, нужно практиковаться.
Что дальше? Мой кот Оши и моя собака Рори любят друг друга и слишком милы, чтобы не запечатлеть их объятия друг с другом, поэтому я начинаю новую серию рисунков в Instagram с хэштегом #canoodledoodle (Canoodle: «Наслаждение чужой компанией путем сближения Обычно это происходит на диване… – Urbandictionary. com).
com).
Я также только что получил новый Apple iPad Pro 12.9 и Apple Pencil в качестве замечательного подарка, так что я буду продвигать свою игру в цифровую сферу, создавать видео и рисовать/писать удаленно.
Я буду постоянно делиться своими дудлами в Instagram и Twitter, но лишь изредка на Facebook. Если хотите, следуйте за мной в моем путешествии по рисованию! И если вы считаете, что какие-то причудливые рисунки от руки подойдут для вашего следующего проекта, я с удовольствием обдумаю несколько идей!
DALL·E: создание изображений из текста
DALL·E — это версия GPT-3 с 12 миллиардами параметров, обученная генерировать изображения из текстовых описаний с использованием набора данных пар текст-изображение. Мы обнаружили, что он обладает разнообразным набором возможностей, включая создание антропоморфных версий животных и объектов, правдоподобное объединение несвязанных концепций, рендеринг текста и применение преобразований к существующим изображениям.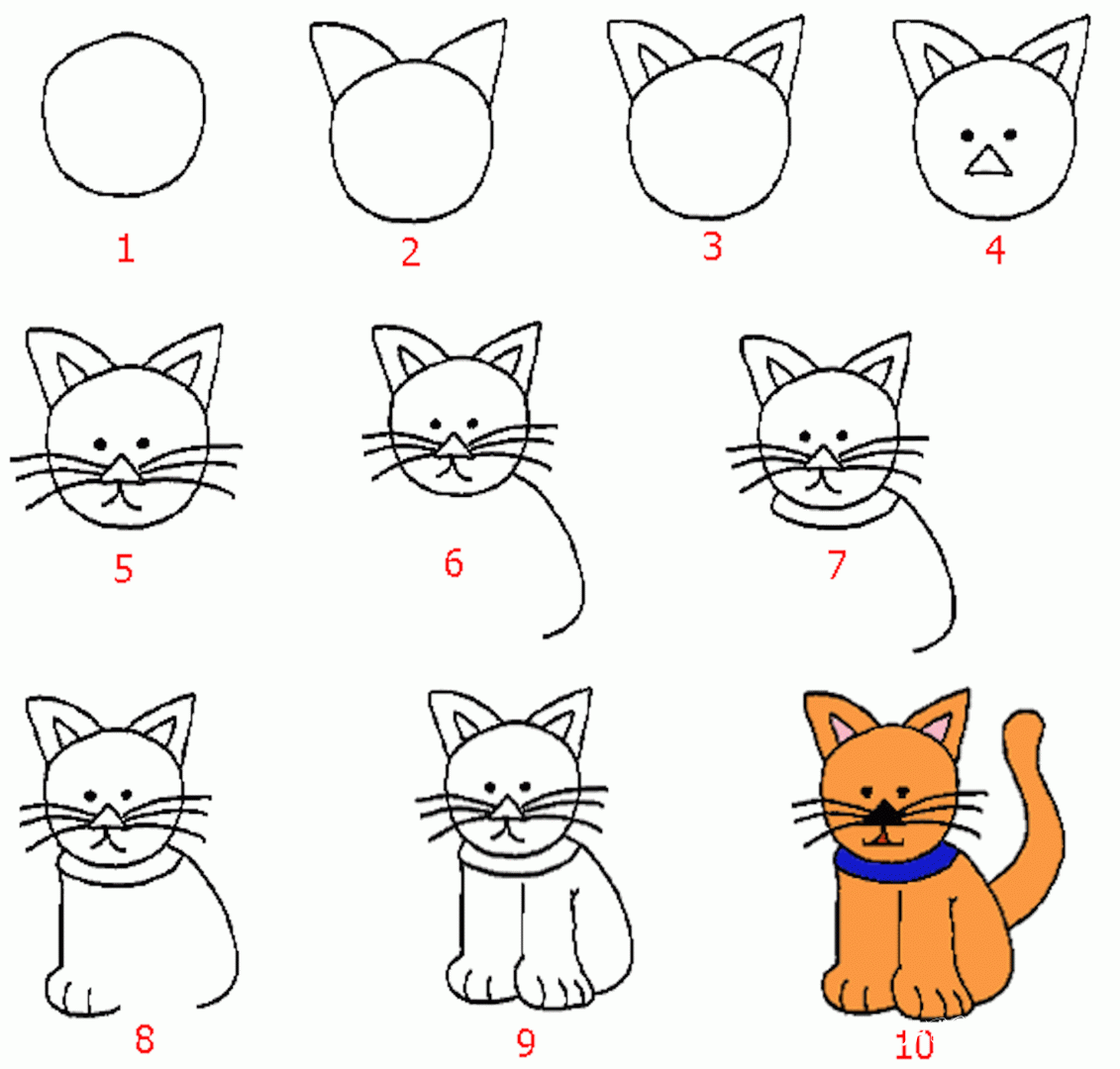
См. также: DALL·E 2 , который создает более реалистичные и точные изображения с 4-кратным увеличением разрешения.
Текстовая подсказка
иллюстрация редиски дайкон в балетной пачке, выгуливающей собаку
Изображения, сгенерированные AI
Текстовая подсказка
кресло в форме авокадо. . . .
AI-генерированные изображения
Текстовая подсказка
витрина магазина, на которой написано слово «openai». . . .
Изображения, созданные искусственным интеллектом
Текстовая подсказка
точно такая же кошка вверху, как и эскиз внизу
Изображения, созданные искусственным интеллектом задач генерации текста. Image GPT показала, что тот же тип нейронной сети можно использовать для создания изображений с высокой точностью. Мы расширяем эти выводы, чтобы показать, что манипулирование визуальными понятиями с помощью языка теперь доступно. 9сноска-1]
Эта процедура обучения позволяет DALL·E не только генерировать изображение с нуля, но и регенерировать любую прямоугольную область существующего изображения, простирающуюся до правого нижнего угла, таким образом, чтобы это соответствовало текстовая подсказка.
Мы понимаем, что работа, связанная с генеративными моделями, может иметь значительные, широкие социальные последствия. В будущем мы планируем проанализировать, как такие модели, как DALL·E, связаны с социальными проблемами, такими как экономическое влияние на определенные рабочие процессы и профессии, потенциальная систематическая ошибка в результатах модели и долгосрочные этические проблемы, связанные с этой технологией.
Возможности
Мы обнаружили, что DALL·E может создавать правдоподобные образы для самых разных предложений, исследующих композиционную структуру языка. Мы проиллюстрируем это с помощью серии интерактивных изображений в следующем разделе. Образцы, показанные для каждой подписи в визуальных элементах, получены путем выбора 32 лучших из 512 после повторного ранжирования с помощью CLIP, но мы не используем никакого ручного выбора, кроме миниатюр и отдельных изображений, которые появляются снаружи. 9сноска-2]
Управление атрибутами
Мы проверяем способность DALL·E изменять несколько атрибутов объекта, а также количество раз, когда он появляется.
Нажмите, чтобы отредактировать текстовую подсказку или просмотреть больше изображений, созданных ИИ. Например, рассмотрим фразу «ежик в красной шапке, желтых перчатках, синей рубашке и зеленых штанах». Чтобы правильно интерпретировать это предложение, DALL·E должен не только правильно скомпоновать каждый предмет одежды с животным, но и сформировать ассоциации (шапка, красный), (перчатки, желтый), (рубашка, синий) и (штаны, зеленый). ) не смешивая их 9сноска-3]
Мы проверяем способность DALL·E делать это для относительного позиционирования, укладки объектов и управления несколькими атрибутами.
Хотя DALL·E предлагает некоторый уровень контроля над атрибутами и позициями небольшого числа объектов, вероятность успеха может зависеть от того, как сформулирован заголовок. По мере того, как вводится больше объектов, DALL·E склонен путать ассоциации между объектами и их цветами, и вероятность успеха резко снижается. Мы также отмечаем, что DALL·E хрупок в отношении перефразирования подписи в этих сценариях: альтернативные, семантически эквивалентные подписи часто не дают правильной интерпретации.
Визуализация перспективы и трехмерности
Мы обнаружили, что DALL·E также позволяет управлять точкой обзора сцены и трехмерным стилем, в котором отображается сцена.
Чтобы продвинуться дальше, мы проверяем способность DALL·E многократно рисовать голову известной фигуры под каждым углом из последовательности равноотстоящих углов и обнаруживаем, что можем восстановить плавную анимацию вращающейся головы.
DALL·E может применять некоторые типы оптических искажений к сценам, как мы видим с параметрами «вид объектива «рыбий глаз»» и «сферическая панорама». Это побудило нас изучить его способность генерировать размышления.
Визуализация внутренней и внешней структуры
Образцы из стилей «очень крупный план» и «рентген» позволили нам дополнительно изучить способность DALL·E визуализировать внутреннюю структуру с помощью поперечных разрезов и внешняя структура с макро фотографиями.
Вывод контекстуальных деталей
Задача преобразования текста в изображения недостаточно конкретизирована: одна подпись обычно соответствует бесконечному количеству правдоподобных изображений, поэтому изображение не определяется однозначно. Например, рассмотрим подпись «картина с изображением капибары, сидящей в поле на восходе солнца». В зависимости от ориентации водосвинки может возникнуть необходимость нарисовать тень, хотя эта деталь никогда не упоминается явно. Мы изучаем способность DALL·E устранять недочеты в трех случаях: изменение стиля, обстановки и времени; рисование одного и того же объекта в различных ситуациях; и создание изображения объекта с написанным на нем определенным текстом.
Например, рассмотрим подпись «картина с изображением капибары, сидящей в поле на восходе солнца». В зависимости от ориентации водосвинки может возникнуть необходимость нарисовать тень, хотя эта деталь никогда не упоминается явно. Мы изучаем способность DALL·E устранять недочеты в трех случаях: изменение стиля, обстановки и времени; рисование одного и того же объекта в различных ситуациях; и создание изображения объекта с написанным на нем определенным текстом.
С различной степенью надежности DALL·E обеспечивает доступ к подмножеству возможностей механизма 3D-рендеринга с помощью естественного языка. Он может независимо контролировать атрибуты небольшого числа объектов и в ограниченной степени, сколько их и как они расположены по отношению друг к другу. Он также может управлять местоположением и углом, с которого визуализируется сцена, и может генерировать известные объекты в соответствии с точными спецификациями угла и условий освещения.
В отличие от механизма 3D-рендеринга, чьи входные данные должны быть указаны однозначно и во всех подробностях, DALL·E часто может «заполнить пробелы», когда заголовок подразумевает, что изображение должно содержать определенную деталь, которая явно не указана.
Применение предыдущих возможностей
Далее мы рассмотрим использование предыдущих возможностей для моды и дизайна интерьера.
Композиционная природа языка позволяет нам объединять концепции для описания как реальных, так и воображаемых вещей. Мы обнаружили, что DALL·E также может комбинировать разрозненные идеи для синтеза объектов, некоторые из которых вряд ли существуют в реальном мире. Мы исследуем эту способность в двух случаях: перенос качеств различных концепций на животных и создание продуктов, черпая вдохновение из несвязанных концепций.
Иллюстрации животных
В предыдущем разделе мы исследовали способность DALL·E комбинировать несвязанные концепции при создании изображений объектов реального мира. Здесь мы исследуем эту способность в контексте искусства для трех видов иллюстраций: антропоморфные версии животных и предметов, химеры животных и смайлики.
Визуальное мышление с нулевым выстрелом
GPT-3 может быть проинструктирован для выполнения многих видов задач исключительно на основе описания и подсказки для получения ответа, указанного в его подсказке, без какого-либо дополнительного обучения. Например, на запрос фразы «вот предложение «человек, выгуливающий свою собаку в парке», переведенное на французский язык:», GPT-3 отвечает: «un homme qui promène son chien dans le parc». Эта возможность называется рассуждения с нулевым выстрелом. Мы обнаружили, что DALL·E расширяет эту возможность до визуальной области и может выполнять несколько видов задач преобразования изображения в изображение при правильном запросе.
Например, на запрос фразы «вот предложение «человек, выгуливающий свою собаку в парке», переведенное на французский язык:», GPT-3 отвечает: «un homme qui promène son chien dans le parc». Эта возможность называется рассуждения с нулевым выстрелом. Мы обнаружили, что DALL·E расширяет эту возможность до визуальной области и может выполнять несколько видов задач преобразования изображения в изображение при правильном запросе.
Мы не ожидали, что эта возможность появится, и не вносили никаких изменений в нейронную сеть или процедуру обучения, чтобы стимулировать ее. Вдохновленные этими результатами, мы измеряем способность ДАЛЛ·И решать задачи на рассуждения по аналогии, проверяя ее на прогрессивных матрицах Равена — визуальном тесте IQ, который широко использовался в 20 веке.
Географические знания
Мы обнаружили, что DALL·E узнал о географических фактах, достопримечательностях и окрестностях. Его знание этих концепций удивительно точно в одних отношениях и ошибочно в других.