Как нарисовать оружие снайпер AWP поэтапно легко
Как нарисовать оружие снайпер AWP поэтапно легко | Ehedov Elnurtourismadjara.ge
Как нарисовать оружие снайпер AWP поэтапно легко | Ehedov Elnur
Play
????Как нарисовать машину Ниву Легко и быстро(Ehedov Elnur)How to Draw a Car Easy Step by Step
Play
Как нарисовать Жигули | Ehedov Elnur
Play
Как нарисовать Самосвал Зил 130 | Ehedov Elnur
Play
Как нарисовать машину Ролс Ройс | Ehedov Elnur
Play
Как нарисовать машину LADA Priora (Ehedov Elnur)
Play
Beşiktaş Vodafone_Besiktas logosu nasil cizilir (Ehedov Elnur) How to draw Besiktas J.K Logo
Play
Как нарисовать машину ВАЗ 2107 поэтапно
Play
Как нарисовать машину Audi R8 поэтапно
Play
Как нарисовать РОЗУ легко?
Play
22=Птичка.. Как нарисовать ПТИЦУ карандашом. Легко!
Play
Как нарисовать пузырь и писать очень легко — буква R
Play
Play
ОРУЖИЕ БУДУЩЕГО. Самое смертоносное оружие в мире.Оружие массового уничтожения в будущем России
Самое смертоносное оружие в мире.Оружие массового уничтожения в будущем России
Play
Снайпер VS Снайпер — Российская СВД против M24 армии США
Play
НОВЫЕ МОДЫ 3D ОРУЖИЕ ,СКИНИ НА ОРУЖИЕ, КРАФТ ОРУЖИЙ В МАЙНКРАФТ ПЕ 1.16
Play
Killing Floor 2 | ЭТО ПЛАТИТ ДЛЯ ВЫИГРЫША? — НОВОЕ ОРУЖИЕ PIRANHA PISTOL DLC! (Возможно, лучшее оружие)
Play
САМОЕ РЕДКОЕ ОРУЖИЕ В РЕЖИМЕ МЕТРО РОЯЛЬ, ЛУЧШЕ ОРУЖИЕ ДЛЯ ИГРЫ PUBG MOBILE METRO ROYALE
Play
Limax.io КАК ЛЕГКО НАБРАТЬ МАССЫ | КАК ЛЕГКО ПОПАСТЬ В ТОП | ТАКТИКИ И СЕКРЕТЫ Limaxio
Play
Оружие МЦ — оружие победы. Ружья МЦ-109, МЦ-106, МЦ-108-04.
Play
Урок редактирования #1 |AVATAN| Поэтапно
Play
Разбираем процесс SLA-печати поэтапно
Play
как сделать простую снежинку из бумаги поэтапно
Play
Asiq Musqulat — YAY GELİR (Elnur Mahmudov) 2020Play
Elnur Bahadurzade — Apar Meni 2021 [Yeni Mahni]
Play
QiziqchilarnI ajoyib qiziqarli rasmlari 2018 (Elnur Egamov)
Play
Как сделать ПАУКА из бумаги, ПОЭТАПНО DIY/Поделки на Хэллоуин/SPIDER out of paper/ Halloween
Play
???? Лёгкий Летний Дизайн Ногтей с Одуванчиком к Яркому Маникюру / Рисунок Гель-лаком Поэтапно
Play
Снайпер Фильм классный
Play
Снайпер Наследие. 2014. HD
2014. HD
Play
Сова VS Снайпер / Из мясокомбината в зоопарк /
Play
Снайпер 1992 США Перу фильм
Play
Снайпер и танцы на двухстороннем «красном»
Play
[ГАЙД] M60 — ЧТО МОЖЕТ СНАЙПЕР ЗА БОНЫ
Play
МАЙНКРАФТ НО СНАЙПЕР КАЖДЫЙ РАЗ ВЗРЫВАЕТСЯ!
Play
Эту песню ищут все (Снайпер 2015)
Play
Снайпер (узбекфильм на русском языке) 2019
Play
Снайпер с ДВЛ-10 • Попали в засаду • Escape from Tarkov №85 [2K]
Play
Searches
- телеканал оружие
- как нарисовать собаку
- как нарисовать розу
- как нарисовать человека
- ჩრდილოეთის ნათება
- tiko sadunishvili
- gug
- კენია
 Но как мы пришли к этому уравнению и как эти геометрические догадки связаны с приведенным выше уравнением?
Но как мы пришли к этому уравнению и как эти геометрические догадки связаны с приведенным выше уравнением? Цель этого поста проста: я хочу объяснить СВД помимо этого определения. Вместо того, чтобы представлять уравнение 111 в его окончательной форме, я хочу построить его на основе первых принципов. Я начну с объяснения SVD без жаргона, а затем формализую объяснение, чтобы дать определение в уравнении 111. Наконец, я обсужу применение SVD, которое продемонстрирует его полезность. В будущих постах я надеюсь доказать существование и уникальность SVD и подробно объяснить рандомизированные SVD.
Этот пост будет в значительной степени опираться на геометрическое понимание матриц. Если вы не знакомы с этой концепцией, пожалуйста, прочитайте мой предыдущий пост на эту тему.
SVD без жаргона
Жаргон полезен при общении в сообществе экспертов, но я обнаружил, что, по крайней мере для себя, легко использовать жаргон, чтобы замаскировать, когда я чего-то не понимаю. Если бы я представил SVD математику, сила жаргона в том, что я мог бы быстро и точно передать ключевые идеи. Обратной стороной является то, что я также мог просто использовать слова, не полностью понимая основную идею, в то время как мой опытный слушатель заполнял пробелы. В качестве упражнения я хочу сначала представить SVD без жаргона, как бы объясняя его заинтересованному 14-летнему ребенку — думаю, уровень математической зрелости восьмого класса. Затем я формализую это интуитивное объяснение, чтобы перейти к стандартной формулировке. Итак, поехали.
Если бы я представил SVD математику, сила жаргона в том, что я мог бы быстро и точно передать ключевые идеи. Обратной стороной является то, что я также мог просто использовать слова, не полностью понимая основную идею, в то время как мой опытный слушатель заполнял пробелы. В качестве упражнения я хочу сначала представить SVD без жаргона, как бы объясняя его заинтересованному 14-летнему ребенку — думаю, уровень математической зрелости восьмого класса. Затем я формализую это интуитивное объяснение, чтобы перейти к стандартной формулировке. Итак, поехали.
Представьте, что у нас есть квадрат. Квадрат, как и ваша рука, образующая букву «L», имеет определенную ориентацию, которую мы графически изображаем стрелками (рис. 111).
Рисунок 1: Квадрат со стрелками.
Мы можем определенным образом манипулировать этим квадратом. Например, мы можем потянуть или нажать на край, чтобы растянуть или сжать квадрат (рис. 2А и 2В). Мы можем повернуть квадрат (рис. 2C) или перевернуть его, чтобы изменить его ориентацию — представьте, что вы переворачиваете руку так, чтобы буква «L» превратилась в «⅃» (рис.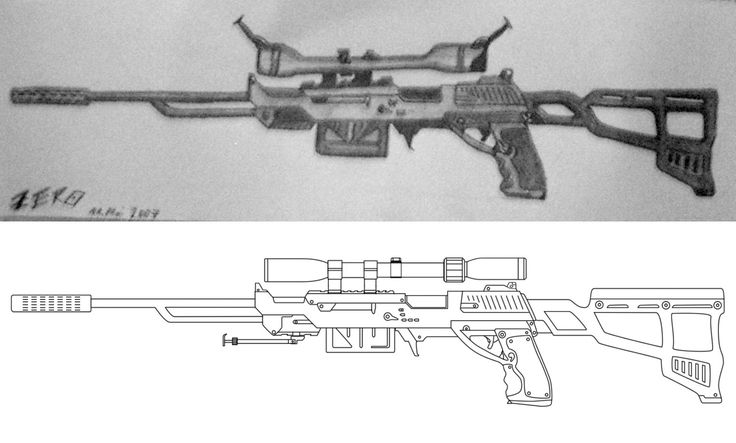 2D). Можем даже сдвиг квадрата, что означает его деформацию путем приложения силы вверх, вниз, влево или вправо к одному из углов квадрата (рис. 2Е).
2D). Можем даже сдвиг квадрата, что означает его деформацию путем приложения силы вверх, вниз, влево или вправо к одному из углов квадрата (рис. 2Е).
Рис. 2. Наш исходный квадрат при различных типах преобразований: (A) растянуто, (B) сжато, (C) повернуто, (D) отражено или перевернуто и (E) сдвинуто.
Единственным ограничением является то, что наше преобразование должно быть линейным . Интуитивно понятно, что линейное преобразование — это преобразование, в котором прямая линия до преобразования приводит к прямой линии после преобразования. Чтобы наглядно представить, что это значит, представьте себе сетку из равномерно расположенных вертикальных и горизонтальных линий на нашем квадрате. Теперь давайте нарисуем диагональную линию на квадрате и проведем некоторую трансформацию. Линейным преобразованием будет такое, при котором после преобразования эта диагональная линия остается прямой (рис. 3В). Чтобы представить нелинейное преобразование на рисунке 3C, представьте, что вы сгибаете лист инженерной бумаги, сжимая две стороны вместе, чтобы он изогнулся посередине. 9{\ простое число} М’ (С).
9{\ простое число} М’ (С).
Теперь, когда мы определили наш квадрат и то, что мы можем с ним сделать, мы можем констатировать классный математический факт. Рассмотрим любое линейное преобразование МММ, которое мы применим к нашему квадрату. Если нам разрешено повернуть наш квадрат на до , применяя МММ, то мы можем найти такое вращение, что сначала применяя поворот, а затем применяя МММ, мы превращаем наш квадрат в прямоугольник. Другими словами, если мы вращаем квадрат перед применением МММ, то МММ просто растягивает, сжимает или переворачивает наш квадрат. Мы можем избежать срезания нашего квадрата.
Давайте представим это на примере. Представьте, что мы разрезали наш квадрат, надавив горизонтально на его верхний левый угол (рис. 4А). В результате получается скошенный квадрат, вроде как старый опрокинутый сарай. Но если бы мы повернули наш квадрат перед тем, как толкнуть его в сторону, сдвиг привел бы только к растяжению и сжатию квадрата, хотя и в новой ориентации (рис. 4В).
4В).
Рисунок 4: Геометрическая сущность SVD: любое линейное преобразование MMM нашего квадрата (A) можно рассматривать как простое растяжение, сжатие или отражение этого квадрата при условии, что мы вращаем квадрат до и после (B).
Это геометрическая сущность СВД. Любое линейное преобразование можно рассматривать как простое растяжение, сжатие или переворачивание квадрата, при условии, что нам разрешено сначала его повернуть. Преобразованный квадрат или прямоугольник может иметь новую ориентацию после преобразования.
Почему это полезно? сингулярных значения , упомянутые в названии «разложение по сингулярным значениям», — это просто длина и ширина преобразованного квадрата, и эти значения могут рассказать вам о многом. Например, если одно из сингулярных значений равно 000, это означает, что наше преобразование сглаживает наш квадрат. И большее из двух сингулярных значений говорит вам о максимальном «действии» трансформации.
Если это второе утверждение не имеет смысла, рассмотрите возможность визуализации нашего преобразования без второго поворота, который никак не влияет на размер прямоугольника. (Представьте, что прямоугольник в нижнем правом подграфике на рис. 4 имеет ту же ориентацию, что и повернутый квадрат в нижнем левом подграфике.) Кроме того, вместо того, чтобы растягивать (или сглаживать) квадрат в прямоугольник, представьте, что круг растягивается в эллипс (через секунду мы увидим, почему) (рис. 5).
(Представьте, что прямоугольник в нижнем правом подграфике на рис. 4 имеет ту же ориентацию, что и повернутый квадрат в нижнем левом подграфике.) Кроме того, вместо того, чтобы растягивать (или сглаживать) квадрат в прямоугольник, представьте, что круг растягивается в эллипс (через секунду мы увидим, почему) (рис. 5).
Рисунок 5: (A) Ориентированный круг; если это поможет, представьте, что этот круг вписан в наш первоначальный квадрат. (B) Наш круг превратился в эллипс. Длины большой и малой осей эллипса имеют значения σ1\sigma_1σ1 и σ2\sigma_2σ2 соответственно, называемые сингулярные значения .
Что геометрически представляет рисунок 5? Большее из двух сингулярных значений является длиной большой оси эллипса. И поскольку мы преобразовали идеальный круг, все возможные радиусы (края круга) были растянуты до края нового эллипса. Какой из этих одинаковых радиусов растянулся больше всего? Та, что тянется по большой оси. Таким образом, радиус, который был растянут больше всего, был растянут на величину, точно равную наибольшему сингулярному значению.
От интуиции к определению
Теперь, когда у нас есть геометрическая интуиция для СВД, давайте формализуем эти идеи. На данный момент я собираюсь предположить, что читатель знаком с основами линейной алгебры. Мы хотим переосмыслить жаргон, чтобы говорить точно и эффективно.
Во-первых, давайте назовем вещи. Напомним, что любая пара ортогональных векторов в двумерном пространстве образует основу для этого пространства. В нашем случае назовем ортогональные векторы во входном пространстве v1\textbf{v}_1v1 и v2\textbf{v}_2v2 (рис. 6А). После применения матричного преобразования MMM к этим двум векторам мы получаем Mv1M \textbf{v}_1Mv1 и Mv2M \textbf{v}_2Mv2 (рис. 6B). Кроме того, давайте разложим эти два преобразованных вектора на единичные векторы, u1\textbf{u}_1u1 и u2\textbf{u}_2u2, умноженные на их соответствующие величины, σ1\sigma_1σ1 и σ2\sigma_2σ2. Другими словами:
Mv1=u1σ1Mv2=u2σ2(2) \begin{выровнено} М \textbf{v}_1 &= \textbf{u}_1 \sigma_1 \\ М \textbf{v}_2 &= \textbf{u}_2 \sigma_2 \end{выровнено} \tag{2} Mv1 Mv2 = u1 σ1 = u2 σ2 (2)
До сих пор мы не сказали ничего нового. Мы просто называем вещи.
Мы просто называем вещи.
Рисунок 6: Формализация геометрической сущности SVD: если мы правильно повернем нашу область, определяемую базисными векторами v1\textbf{v}_1v1 и v2\textbf{v}_2v2, то любое линейное преобразование MMM будет просто преобразованием диагональной матрицей (расширяющейся, отражающей) в потенциально повернутом диапазоне, определяемом u1\textbf{u}_1u1 и u2\textbf{u}_2u2.
Но теперь, когда у нас есть названия вещей, мы можем сделать небольшую алгебраическую операцию. Во-первых, обратите внимание, что любой вектор x\textbf{x}x может быть описан с помощью базисных векторов v1\textbf{v}_1v1 и v2\textbf{v}_2v2 следующим образом:
x=(x⋅v1 )v1+(x⋅v2)v2(3) \textbf{x} = (\textbf{x} \cdot \textbf{v}_1) \textbf{v}_1 + (\textbf{x} \cdot \textbf{v}_2) \textbf{v}_2 \ тег{3} x=(x⋅v1)v1+(x⋅v2)v2(3)
, где a⋅b\textbf{a} \cdot \textbf{b}a⋅b обозначает скалярное произведение между векторами a \textbf{a}а и б\textbf{b}б. Если вы не уверены в приведенной выше формулировке, рассмотрите аналогичную формулировку со стандартными базисными векторами:
х=х1[10]+х2[01] \textbf{x} = x_1 \begin{bmatrix} 1 \\ 0 \end{bmatrix} + x_2 \begin{bmatrix} 0 \\ 1 \end{bmatrix} x=x1[10]+x2[01]
, где xix_ixi обозначает iii-ю компоненту x\textbf{x}x. В уравнении 333 мы проецируем через скалярное произведение x\textbf{x}x на v1\textbf{v}_1v1 и v2\textbf{v}_2v2 перед разложением членов с использованием базисных векторов v1\textbf {v}_1v1 и v2\textbf{v}_2v2.
В уравнении 333 мы проецируем через скалярное произведение x\textbf{x}x на v1\textbf{v}_1v1 и v2\textbf{v}_2v2 перед разложением членов с использованием базисных векторов v1\textbf {v}_1v1 и v2\textbf{v}_2v2.
Далее, давайте умножим обе части уравнения 333 слева на наше матричное преобразование МММ. Поскольку скалярное произведение дает скаляр, мы можем распределить и коммутировать МММ следующим образом:
Мх=(х⋅v1)Mv1+(x⋅v2)Mv2 M \textbf{x} = (\textbf{x} \cdot \textbf{v}_1) M \textbf{v}_1 + (\textbf{x} \cdot \textbf{v}_2) M \textbf{v }_2 Mx=(x⋅v1)Mv1+(x⋅v2)Mv2
Далее мы можем переписать MviM \textbf{v}_iMvi как uiσi\textbf{u}_i \sigma_iuiσi:
Мх=(х⋅v1)u1σ1+(x⋅v2)u2σ2 M \textbf{x} = (\textbf{x} \cdot \textbf{v}_1) \textbf{u}_1 \sigma_1 + (\textbf{x} \cdot \textbf{v}_2) \textbf{u }_2 \сигма_2 Mx=(x⋅v1)u1σ1+(x⋅v2)u2σ2
Мы почти у цели. Теперь, поскольку точечный продукт коммутативен, мы можем изменить порядок, например. x⋅v1=x⊤v1=v1⊤x\textbf{x} \cdot \textbf{v}_1 = \textbf{x}^{\top} \textbf{v}_1 = \textbf{v}_1^{ \top} \textbf{x}x⋅v1=x⊤v1=v1⊤x. {\top}}
\тег{5}
M=U[[u1u2]Σ[[σ100σ2]V⊤[[v1⊤v2⊤](5)
{\top}}
\тег{5}
M=U[[u1u2]Σ[[σ100σ2]V⊤[[v1⊤v2⊤](5)
Более того, вы должны интуитивно понимать, что это значит. Любое матричное преобразование может быть представлено как диагональное преобразование (расширяющее, отражающее), определяемое Σ\SigmaΣ, при условии, что домен и диапазон сначала правильно повернуты.
Векторы ui\textbf{u}_iui называются левыми сингулярными векторами, а векторы vi\textbf{v}_ivi называются правыми сингулярными векторами. Эта ориентирующая терминология немного сбивает с толку, потому что «лево» и «право» берутся из приведенного выше уравнения, в то время как на наших диаграммах прямоугольников и эллипсов векторы vi\textbf{v}_ivi находятся слева.
Стандартная формулировка
Теперь, когда у нас есть простая геометрическая интуиция для СВД и формализована она для всех матриц 2×22 \× 22×2, давайте переформулируем задачу в общем и стандартном виде. Если переход от 222-мерного к nnn-измерению затруднен, вспомните совет Джеффа Хинтона:
Чтобы иметь дело с гиперплоскостями в 14-мерном пространстве, визуализируйте трехмерное пространство и очень громко скажите себе «четырнадцать».
Все это делают.
 Все это делают.
Все это делают.Учтите, что, учитывая наши определения vi\textbf{v}_ivi, ui\textbf{u}_iui и σi\sigma_iσi, мы можем переписать уравнение 222 для произвольной матрицы m×nm \times nm×n MMM как:
[M][v1v2…vn]=[u1u2…um][σ1σ2⋱σn] \begin{bматрица} \\ \\ & & М & & \\ \\ \\ \end{bmatrix} \left[\begin{массив}{с|с|с|с} \\ \textbf{v}_1 & \textbf{v}_2 & \dots & \textbf{v}_n \\ \\ \конец{массив}\справа] «=» \left[\begin{массив}{с|с|с|с} \\ \\ \textbf{u}_1 & \textbf{u}_2 & \dots & \textbf{u}_m \\ \\ \\ \конец{массив}\справа] \begin{bматрица} \sigma_1 & & & \\ & \sigma_2 & & \\ & & \ddots & \\ & & & \sigma_n \\ \\ \end{bmatrix} ⎣⎢⎢⎢⎢⎢⎡M⎦⎥⎥⎥⎥⎥⎤⎣⎢⎡v1v2…vn⎦⎥⎤=⎣⎢⎢⎢⎢⎢⎡ u1u2…um⎦⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎡σ1σ2⋱σn⎦⎥⎥⎥⎥⎥⎤ 9{\top}V⊤ — ортонормированные правые сингулярные векторы. Пунктирные области являются отступами.
Диагональные элементы Σ\SigmaΣ являются сингулярными числами. Без ограничения общности можно предположить, что сингулярные значения упорядочены — для их упорядочения может потребоваться переупорядочение столбцов UUU и VVV. И геометрическая интерпретация их сохраняется в более высоких измерениях. Например, если мы выполнили SVD на матрице m×nm \times nm×n и заметили, что нижние сингулярные значения kkk были меньше некоторого эпсилона, вы могли бы визуализировать это матричное преобразование как сглаживание гиперэллипса вдоль этих kkk измерений. Или, если у вас есть экспоненциальный спад значения сингулярных значений, это предполагает, что все «действие» матрицы происходит только в нескольких измерениях.
И геометрическая интерпретация их сохраняется в более высоких измерениях. Например, если мы выполнили SVD на матрице m×nm \times nm×n и заметили, что нижние сингулярные значения kkk были меньше некоторого эпсилона, вы могли бы визуализировать это матричное преобразование как сглаживание гиперэллипса вдоль этих kkk измерений. Или, если у вас есть экспоненциальный спад значения сингулярных значений, это предполагает, что все «действие» матрицы происходит только в нескольких измерениях.
Вот и все! Это СВД. Вы можете прочитать о различиях между полной и усеченной SVD, об обработке матриц низкого ранга и т. д. в более качественных ресурсах, чем этот. Моя цель состояла в том, чтобы прийти к уравнению 111 с помощью как можно более простых рассуждений. По крайней мере, на мой взгляд, медленное рассмотрение геометрической интуиции делает объяснения СВД более осмысленными.
Повторная визуализация SVD
Теперь, когда мы понимаем SVD, мы можем убедиться, что визуализировали его правильно. Рассмотрим рис. 8, созданный с использованием Matplotlib и реализации SVD в NumPy,
Рассмотрим рис. 8, созданный с использованием Matplotlib и реализации SVD в NumPy, numpy.linalg.svd . Мы видим, что эти цифры в точности совпадают с нашими интуитивными представлениями о том, что происходит с СВД в 222-м измерении.
Рис. 8. Несколько примеров использования реализации SVD в NumPy для визуализации алгоритма. Каждый кадр имеет две пары наложенных друг на друга прямоугольников. Для каждой пары квадрат преобразуется в параллелограмм линейным преобразованием. В левой паре квадрат не повернут. В правой паре квадрат поворачивается на VVV перед применением преобразования. Каждая пунктирная линия — это верхний сингулярный вектор для связанного преобразования.
Приложения
SVD связан со многими другими свойствами матрицы. Количество ненулевых сингулярных значений равно рангу матрицы. Вот почему спектральная норма является выпуклым заменителем аппроксимаций низкого ранга. Областью матрицы является пространство, натянутое на векторы {u1,u2,…,ur}\{\textbf{u}_1, \textbf{u}_2, \dots, \textbf{u}_r\}{u1 ,u2,…,ur} где rrr — количество ненулевых сингулярных значений, а все сингулярные значения и векторы упорядочены. Матрица необратима, если она имеет сингулярное значение, равное нулю, потому что преобразование «схлопывает» nnn-куб по крайней мере в одном измерении. И так далее. Как только вы поймете, что такое SVD, я думаю, что интуитивно понять 9 будет довольно просто.0023 почему вышеупомянутые свойства должны сохраняться. Подробности см. в главе 5 (Trefethen & Bau III, 1997).
Матрица необратима, если она имеет сингулярное значение, равное нулю, потому что преобразование «схлопывает» nnn-куб по крайней мере в одном измерении. И так далее. Как только вы поймете, что такое SVD, я думаю, что интуитивно понять 9 будет довольно просто.0023 почему вышеупомянутые свойства должны сохраняться. Подробности см. в главе 5 (Trefethen & Bau III, 1997).
Один из алгоритмов, который мне намного легче понять после понимания SVD, — это анализ основных компонентов (PCA). Вместо того, чтобы предполагать, что вы знаете, как работает PCA, давайте посмотрим, что вычисляет PCA, а затем давайте рассуждать о том, что PCA делает с нашими знаниями о SVD. Рассмотрим матрицу данных с действительным знаком XXX, которая имеет размер n × pn \times pn × p, где nnn — количество выборок, а ppp — количество признаков. Его СВД 9{\ вверх} U = IU ⊤ U = I. И даже не зная о собственных векторах или собственных значениях, мы можем увидеть, что делает PCA, поняв SVD: это диагонализация ковариационной матрицы XXX . Таким образом, PCA находит основные оси, по которым изменяются наши данные.
Таким образом, PCA находит основные оси, по которым изменяются наши данные.
Если непонятно, что означает SVD или собственное разложение данных, Джереми Кун написал об этом хороший пост в блоге.
Заключение
Разложение по сингулярным числам или SVD — мощный инструмент в линейной алгебре. Понимание того, что декомпозиция представляет геометрически, полезно для понимания других свойств матрицы, а также помогает нам лучше понять алгоритмы, основанные на SVD.
Благодарности
Для написания этого поста мне потребовалось синтезировать информацию из ряда превосходных источников. В частности, для вывода в разделе, формирующем SVD, я использовал этот учебник от Американского математического общества. Я благодарю Махмуда Абдельхалека и Альфредо Канциани за то, что они обратили мое внимание на опечатки.
Разложение по единственному значению (SVD) — рабочий пример | Рошан Джо Винсент | Intuition
Недавно я начал изучать рекомендательные системы и, в частности, совместную фильтрацию, в которой входная матрица оценок пользователей разбивается на 3 матрицы пользовательских функций, функций-функций и матриц элементов-функций с использованием метода, называемого Singular Value. Разложение (СВД). Прежде чем я применил это, я хотел получить интуитивное понимание математики, стоящей за этим, и таким образом начал свое недельное путешествие в мир матричной декомпозиции. Ну, я не был одним из тех математиков в школе, поэтому я потерялся во многих учебниках по SVD, потому что они пропустили некоторые шаги, такие как 9.0023 вычисление строчно-ступенчатой формы, нулевое пространство матрицы. и т. д. Итак, я начал изучать и углубляться в то, как на самом деле работает SVD и как формируются эти три матрицы, например, как заданная входная матрица разлагается на эти три матрицы. В этой истории я буду рассматривать пример SVD и математически разбивать весь процесс. Итак, начнем!
Разложение (СВД). Прежде чем я применил это, я хотел получить интуитивное понимание математики, стоящей за этим, и таким образом начал свое недельное путешествие в мир матричной декомпозиции. Ну, я не был одним из тех математиков в школе, поэтому я потерялся во многих учебниках по SVD, потому что они пропустили некоторые шаги, такие как 9.0023 вычисление строчно-ступенчатой формы, нулевое пространство матрицы. и т. д. Итак, я начал изучать и углубляться в то, как на самом деле работает SVD и как формируются эти три матрицы, например, как заданная входная матрица разлагается на эти три матрицы. В этой истории я буду рассматривать пример SVD и математически разбивать весь процесс. Итак, начнем!
Согласно формуле для SVD,
SVD Формула- A — входная матрица
- U — левые сингулярные векторы,
- сигма — диагональ/собственные значения
- V — правые сингулярные векторы.
Форма этих трех матриц будет
- A — m x n матрица
- U — m x k матрица
- Sigma — k x k матрица
- V — n x k матрица
собственные значения (посмотрите видео, представленное ниже, чтобы получить представление о собственных значениях и собственных векторах) матрицы A, и поскольку A может быть прямоугольной матрицей, нам нужно преобразовать ее в квадратную матрицу, умножив A на ее транспонирование. Здесь для облегчения вычислений я взял A как матрицу 2 x 2.
Здесь для облегчения вычислений я взял A как матрицу 2 x 2.
Теперь, когда у нас есть квадратная матрица, мы можем вычислить собственные значения A(транспонировать) A. Мы можем сделать это, вычислив определитель A(транспонировать)A — (лямбда)I, где лямбда — это два собственных значения.
Решая уравнение, мы получаем
Собственные значенияПосле того, как мы вычислили собственные значения, пришло время вычислить два собственных вектора для каждого собственного значения. Итак, начнем с вычисления собственного вектора для 10.
Шаг 3.1
Подставляем значение лямбда в матрицу A(транспонирование)A — (лямбда)I.
Чтобы найти собственный вектор, нам нужно найти нулевое пространство матрицы, где AB = 0. Другими словами,
Формула нулевого пространстваЗатем нам нужно привести эту матрицу к форме строки-эшелона, чтобы мы можно легко решить уравнение. Давайте немного поговорим о Row-Echelon здесь.
Строко-Эшелонная Форма
Говорят, что матрица находится в ступенчато-строковой форме, если выполняются следующие правила.
- Все ведущие элементы в каждой строке матрицы равны 1
- Если столбец содержит ведущую запись, то все записи ниже ведущей записи должны быть равны нулю
- Если любые две последовательные ненулевые строки, ведущая запись в верхней строке должна находиться слева от ведущей записи в нижней ряд.
- Все строки, состоящие только из нулей, должны находиться в нижней части матрицы.
Нам нужно выполнить некоторые операции над строками, чтобы уменьшить матрицу. Эти операции называются элементарными операциями со строками , и есть определенные правила, которым необходимо следовать для этих операций, как указано ниже,
https://en.wikibooks.org/wiki/Linear_Algebra/Row_Reduction_and_Echelon_FormsВооружившись приведенными выше правилами, давайте начнем уменьшать матрицу в Шаг 3.1 до рядно-кулисная форма.
Строковая форма для матрицы, упомянутой в шаге 3.1Теперь мы можем решить для нулевого пространства, как показано ниже, чтобы найти собственный вектор для собственного значения 10
Как только мы получим этот вектор, нам нужно преобразовать его в единичный вектор . Мы делаем это, беря столбцовые значения и разделяя их на квадратный корень из суммы квадратов значений. Итак, в этом случае мы делаем следующее:
Мы делаем это, беря столбцовые значения и разделяя их на квадратный корень из суммы квадратов значений. Итак, в этом случае мы делаем следующее:
Таким образом, окончательный собственный вектор для собственного значения равен
Мы делаем аналогичные шаги, чтобы получить собственный вектор для собственного значения 40
Матрица для вычисления Строка-Эшелон FormEigenVector для 40Теперь, когда мы получили оба собственные векторы, давайте сложим их вместе.
Обратите внимание, что диагональные значения в сигме всегда находятся в порядке убывания, поэтому векторы также размещаются в соответствующем порядке. Если вы знакомы с PCA, главные компоненты соответствуют верхнему k диагональному элементу, который отражает наибольшую дисперсию. Чем выше значение, тем важнее компонент и тем большую дисперсию он описывает.
Теперь, когда у нас есть матрицы V и Sigma, пришло время найти U. Мы можем просто умножить уравнение на сигму (обратное) и V с обеих сторон, чтобы получить уравнение для U. В этом случае, поскольку V является ортогональная матрица, транспонированная и обратная V одинаковы, поэтому V (транспонированная), умноженная на V, становится единичной матрицей. То же самое касается и диагональной матрицы.
В этом случае, поскольку V является ортогональная матрица, транспонированная и обратная V одинаковы, поэтому V (транспонированная), умноженная на V, становится единичной матрицей. То же самое касается и диагональной матрицы.
Примечание. С левой стороны это сигма (инверсия), а не транспонирование, как указано на слайде ниже 9.0024
Вычисление A x VДалее нам нужно преобразовать это в единичные векторы, используя шаги, описанные выше.
AV как единичные векторыЗатем мы умножаем эту матрицу на сигму (транспонирование), которая сама по себе является сигмой, потому что это диагональная матрица.
AV x sigma (транспонировать) Теперь нам нужно преобразовать это в единичные векторы, чтобы получить окончательную матрицу U. UИтак, мы вычислили U, сигму и V и разложили матрицу A на три матрицы, как показано ниже.
СВДВы можете убедиться в этом, зайдя в этот милый инструмент и выполнив умножение матриц.
Понимание того, как рассчитать SVD, а также теоретическое понимание помогло мне получить более интуитивное представление о его приложениях, таких как PCA, совместная фильтрация. и т. д. Вы также можете разложить матрицу, используя разложение по собственным числам, но преимущество SVD перед разложением по собственным числам заключается в том, что SVD работает даже для прямоугольных матриц.
и т. д. Вы также можете разложить матрицу, используя разложение по собственным числам, но преимущество SVD перед разложением по собственным числам заключается в том, что SVD работает даже для прямоугольных матриц.
Примечание: Математические руководители прокомментируют в разделе ниже, если есть ошибка, и я сделаю все возможное, чтобы исправить ее. Цель этой истории состояла в том, чтобы дать понимание вычислений и дать людям, которые плохо знакомы с линейной алгеброй и изучают SVD, универсальный магазин для всех различных компонентов.
Спасибо, что прочитали.
Ссылки
- Форма эшелона строк — https://www.youtube.com/watch?v=biW3S9EdE4w
- Пустое пространство — https://www.cliffsnotes.com/study-guides/алгебра/linear- алгебра/реальное-евклидово-векторное-пространство/нулевое-пространство-матрицы
- Вычисление нулевого пространства — http://www.math.odu.edu/~bogacki/cgi-bin/lat.cgi
- Горное дело массивных наборов данных — https://www.
